Understanding LangChain's MapReduceChain
I have been experimenting with LangChain, an open-source framework for developing applications powered by language models, as I venture into the world of AI and LLMs. Being primarily a JavaScript/TypeScript developer, I have been using the JS port of LangChain. Unfortunately, it is not yet at feature parity as the Python version. So when I ran into a missing feature, I decided to implement it and contribute back to this amazing library.
Whilst going through the source code, one of the items that I touched was the MapReduceChain function. I had to understand what it does and how it works before I could implement the missing feature. So I decided to write this article to document my understanding of it.
All the details in here is based on the JS port of LangChain. The Python implementation might have some slight differences.
What is MapReduceChain?
MapReduceChain is one of the document chains inside of LangChain. It’s function is to basically take in a list of documents (pieces of text), run an LLM chain over each document, and then reduce the results into a single result using another chain. A simple concept and really useful when it comes to dealing with large documents.
How does it work?
If you are familiar with the concept of MapReduce then it is basically that and you can probably explain it better than I could. But for those that are not familiar with it, I will try to explain it in simple terms.
Although the high-level concept is the same, let’s dive in and see how the implementation was done in LangChain. First let’s see the inputs required for this chain.
| input | description |
|---|---|
input_documents | A list of documents to be processed |
llmChain | The LLM chain to be run on each document |
combineDocumentChain | The chain to be run on the results of the LLM chain |
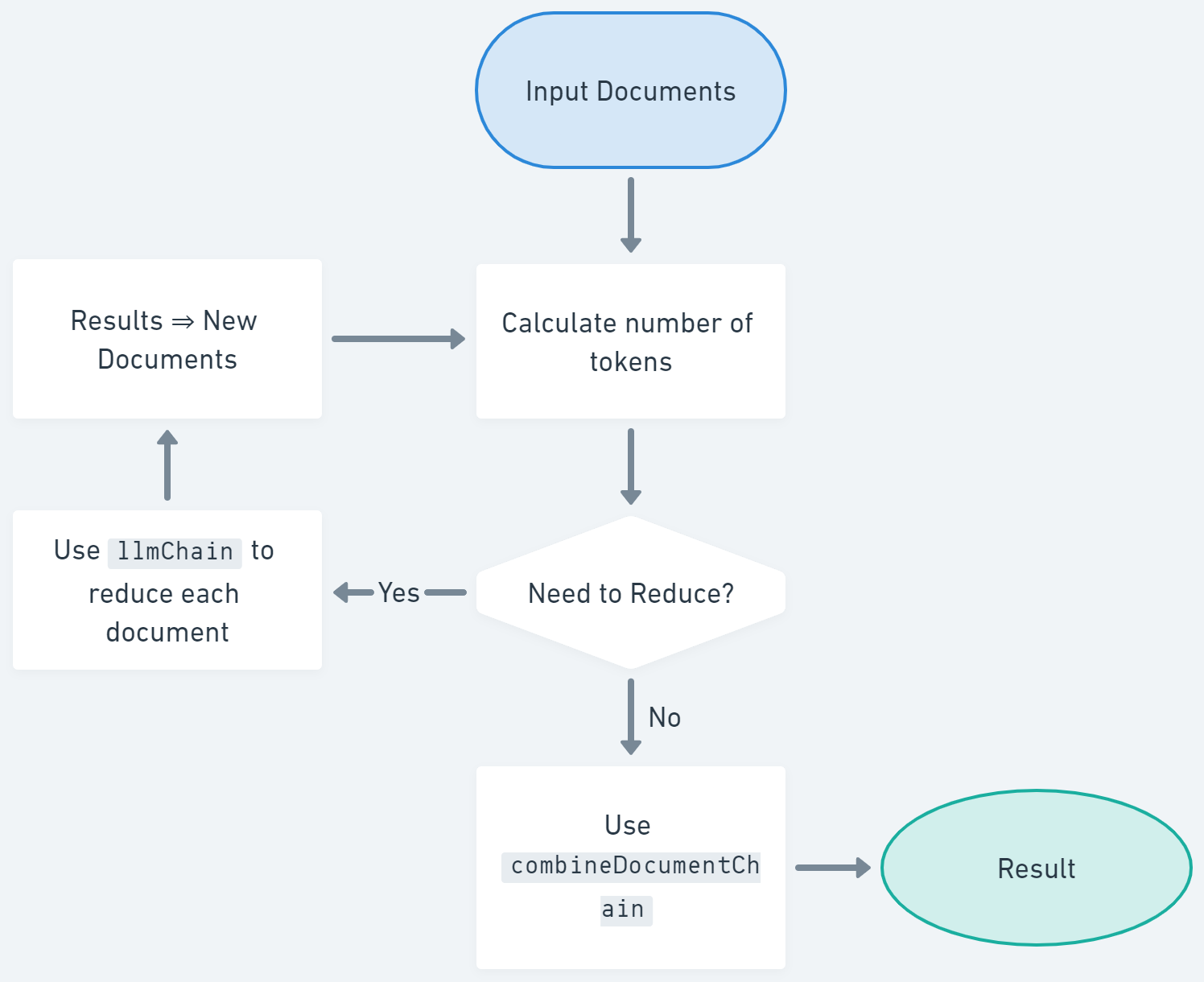
So from there, the process goes like this:
- Place all documents into the prompt template of
llmChainand get the number of tokens it requires to run thellmChain - If the tokens required is less than the maximum allowed, then we do not need to reduce anything and you can skip straight to step 6.
- If the tokens required is more than the maximum allowed, then we need to split the documents into smaller chunks.
- For each document chunk, run the
llmChainand get the results. - Save these results as the new list of documents to use as input, and start again for step 1.
- Now that the documents can fit into the maximum allowed tokens, run the
combineDocumentChainon the list of documents and return the result.
Here’s a flow-chart that might help visualize that a bit better.
What can I use this for?
As you can tell, this allows you to reduce large documents into smaller chunks so that you can still send the data through to any LLMs that will generally have a token limit. This is especially useful when you are dealing with large documents such as books, articles, or even long-form text. So some great use cases for this would be to summarize a book, or to generate a summary of a long article.
Here’s a quick example of how you can use this to summarize a book.
import { readFileSync } from 'fs';
import { loadSummarizationChain } from 'langchain/chains';
import { OpenAI } from 'langchain/llms/openai';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
const main = async () => {
const text = readFileSync('some-super-long-book.txt', 'utf8');
const model = new OpenAI({ temperature: 0 });
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: 1000 });
const docs = await textSplitter.createDocuments([text]);
const chain = loadSummarizationChain(model, {
type: 'map_reduce',
// The prompt passed to `llmChain`
combineMapPrompt: new PromptTemplate({
template: `Write a summary of the following in 1-2 sentences:
"{text}"
SUMMARY:
`,
inputVariables: ['text'],
}),
// The prompt passed to `combineDocumentChain`
combinePrompt: new PromptTemplate({
template: `From the following text, summarize it in French:
"{text}"
FRENCH SUMMARY:
`,
}),
});
const res = await chain.call({ input_documents: docs });
console.log(res);
};
main();
In the code above, it will basically create a 1-2 summary for each part of the book (chunked to 1000 characters) and then combine all the summaries into a single summary in French. This is a very simple example, but you can see how powerful this can be.
Let me know what you think of this. Was this useful and would you like to see more of these types of articles? What are some projects or ideas that you’d like to test this out on? Reach out to me via LinkedIn or email if you’d like my help.