Getting structured data using OCR and AI

If you’ve been following my 12 startups journey, you might remember that one of my projects is a festival listing website called Festack. One of the issues with such a site is keeping the information up-to-date and I’ve been looking for a way to automate the process of adding new festivals to the site. Web-scraping proofed to be challenging as every single festival has their own custom site and some even change their entire site each year.
Recently, I’ve been exposed more and more to the capabilities of OpenAI’s GPT and I thought it might be a good fit for this problem. So I wondered if I could combine some scraping with GPT to get the data I needed. So I went and trialed it out on a few different festival websites, but unfortunately it did not work out. Issues with the data being inconsistent, information being spread across many pages and just the fact that the HTML is quite large and complex.
After talking to a friend of mine, discussing similar issues that she was running into with her project, it came to me. Almost every single music festival has a poster that has most of the information I’d want. So I thought, why not use OCR (Optical Character Recognition) to extract the text from the poster and then use GPT to summarize that information into a structured format that I can use! So, here is the result of that experiment.
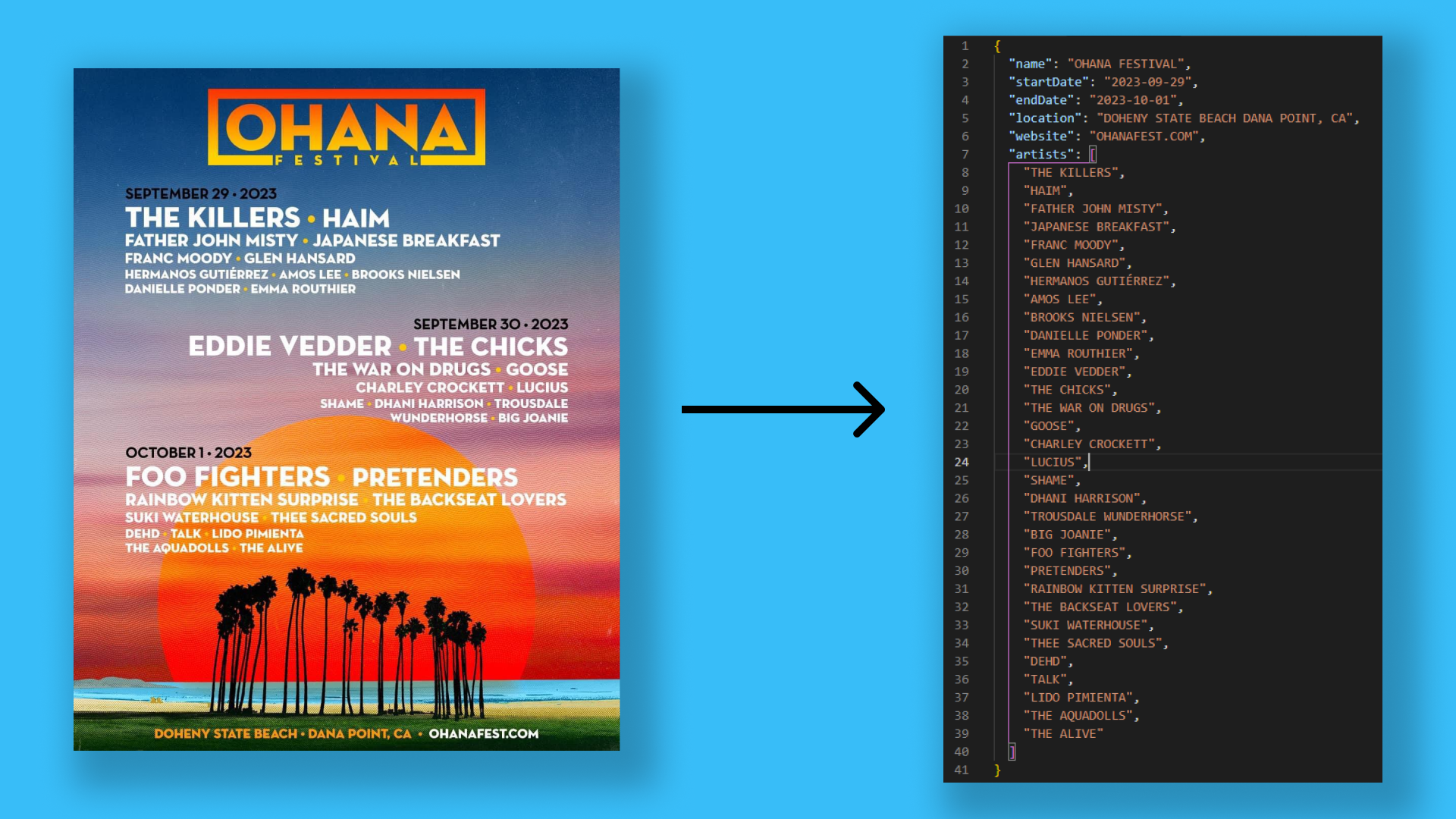
Pretty cool huh? I’m pretty happy with the results. I definitely won’t be saving that data directly into the database, as I still find some discrepancies every now and then. But it does get 80% off the work done faster. Alright, let’s get technical now and dive in to how I did it.
Everything here was done in the AWS ecosystem, using SST as the Infrastructure as Code framework.
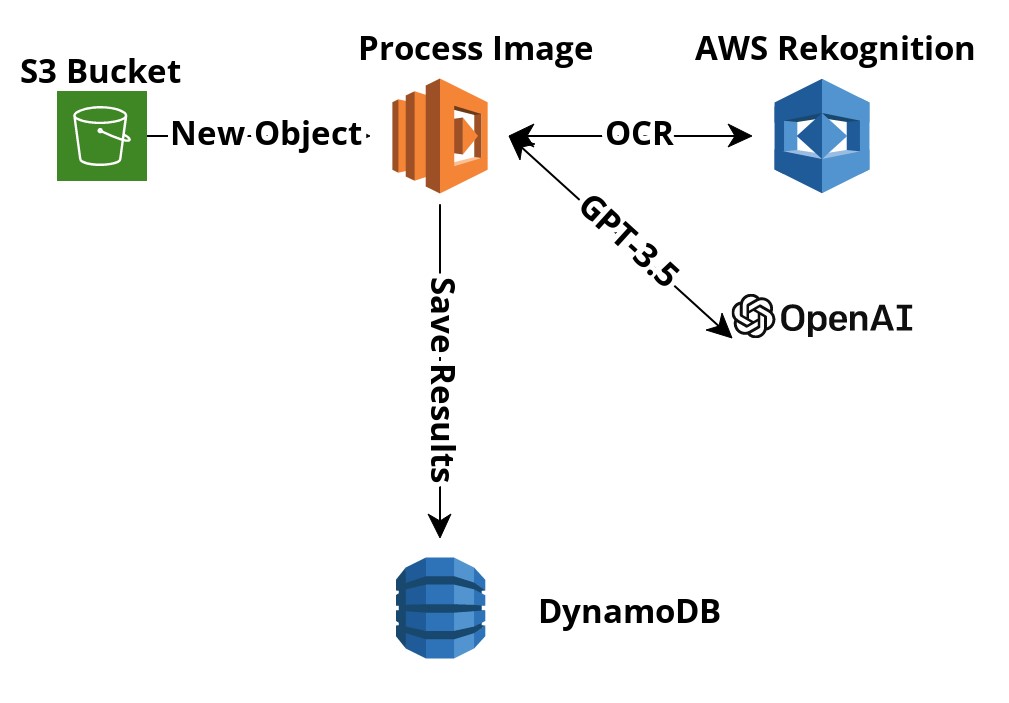
Firstly, I created a lambda function that would be triggered whenever a new image was uploaded into S3. Using the event details, I then send that to AWS Rekognition to extract the text from the image. Now the text is returned in a JSON format, and it is very verbose, it includes a lot of information like where the text was located in the image, how confident it is that it is the correct text, etc. Through testing, I’ve found that all I needed is just the text itself for each line. So I wrote a small script to clean up the data before sending it.
// Infrastructure code
export const ScraperStack = ({ stack, app }: StackContext) => {
const db = use(DatabaseStack);
const openAI = Secret.create(stack, 'OPENAI_API_KEY');
new Bucket(stack, 'ScraperBucket', {
notifications: {
objectCreated: {
function: {
handler: 'services/functions/scraper/object-created.handler',
bind: [db, openAI.OPENAI_API_KEY],
},
events: ['object_created'],
filters: [{ prefix: 'new/' }],
},
},
});
};
// Lambda code to handle when the object is created
// services/functions/scraper/object-created.ts
export const handler: S3Handler = async (evt) => {
// There might be a few records at a time, so loop through it.
for (const record of evt.Records) {
const { key, versionId } = record.s3.object;
// Detect text
const ocrResult = await detectText({
Bucket: record.s3.bucket.name,
Name: key,
Version: versionId,
});
// Clean out the data
const cleanedOcrResult = (ocrResult || [])
.filter((val) => val.Type === 'LINE')
.map((val) => val.DetectedText);
// Send to OpenAI
const res = await parseOCRThroughOpenAI(JSON.stringify(cleanedOcrResult));
// Do something with the result
console.log(res);
}
};
// OCR Function
import {
DetectTextCommand,
RekognitionClient,
S3Object,
} from '@aws-sdk/client-rekognition';
const client = new RekognitionClient({});
export async function detectText(s3Object: S3Object) {
const command = new DetectTextCommand({
Image: { S3Object: s3Object },
});
const result = await client.send(command);
return result.TextDetections;
}
Armed with the cleaned up text, I then utilized LangChain to send that text over to OpenAI and summarize it to get some data that I want out of it.
// LangChain Function
export async function parseOCRThroughOpenAI(ocrResult: string) {
const model = new OpenAI({
openAIApiKey: Config.OPENAI_API_KEY,
temperature: 0,
modelName: 'gpt-3.5-turbo',
});
const parser = StructuredOutputParser.fromNamesAndDescriptions({
name: 'The name of the festival',
startDate: 'Start date of the festival in ISO-8601 format',
endDate: 'End date of the festival in ISO-8601 format',
location: 'The location of the festival',
website: 'The website of the festival',
artists: 'An array of artists at the festival',
});
const formatInstructions = parser.getFormatInstructions();
const prompt = new PromptTemplate({
template:
'You are a tool that translates OCR results into structured data.\n{formatInstructions}\nOCR Result:\n"""{ocrResult}"""',
inputVariables: ['ocrResult'],
partialVariables: { formatInstructions: formatInstructions },
});
const input = await prompt.format({
ocrResult,
});
const response = await model.call(input);
return parser.parse(response);
}
And that’s it! Surprisingly very easy to do! You can now do whatever you want with this data. Currently I’m saving it into the database so that I can review the information and then approve each one, just to monitor the results first.
Let me know what you think about this experiment and if you have any ideas on how I can improve it. Do you have projects that you’d like to test this out on? Reach out to me via LinkedIn or email if you’d like my help.